Prompt management
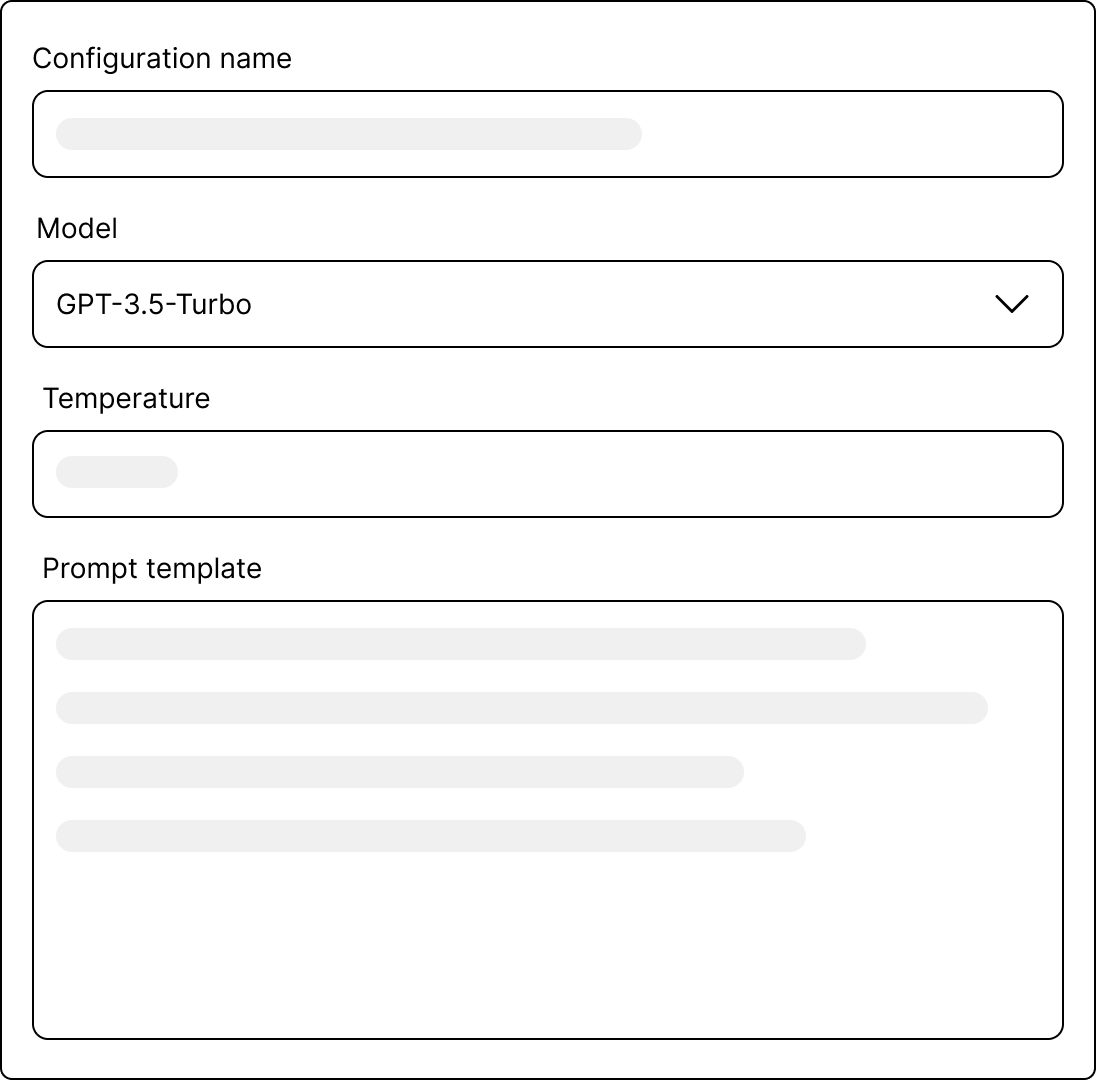
AB Prompt allows you to manage all your prompt configurations directly in your workspace. To create a new prompt, you'll need to
provide a prompt name, select an LLM model (e.g., gpt-3.5-turbo or gpt-4), set the temperature, and define a prompt template.
Template Variables
Use the {{ variableName }} syntax to insert dynamic data into your prompt template.
Example
Here's a template that asks for a summary of a paragraph:
In point form, summarize the following paragraph:
{{ paragraph }}
This lets you plug in the paragraph variable dynamically when making an API call.
How it works
Set up a prompt configuration
Using the UI, create a prompt configuration by providing a name, temperature, and prompt template. To insert dynamic data, use the
{{ templateVariable }}syntax.Make an API call
Each prompt configuration gets its own unique API endpoint. To make an inference call, your application's server sends a POST request to this endpoint. Include the following in your request:
- AB Prompt API key
- An OpenAI API key
- Template variables
- Optional metadata (e.g., user IDs, timestamps)
Prompt rendering and response
AB Prompt first renders the prompt template and then forwards the request to the selected LLM provider. Upon receiving the inference results, it logs essential details such as input, output, token usage, and response times. Finally, all logged information and inference results are sent back to your application's server.